【论文笔记】Robust Federated Learning With Noisy and Heterogeneous Clients
0 Paper Info
原文地址:Robust Federated Learning With Noisy and Heterogeneous Clients
录用会议:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR
录用年份:2022
1 Introduction
论文旨在解决横向联邦学习场景(Server-Client架构)下各个客户端模型异构(个性化联邦学习),且标签集存在噪声的情况
1.1 Federated Learning
自FedAvg提出来之后,陆续出现了很多联邦学习场景下的工作,但现有的算法通常都是基于所有客户端都拥有无噪声的干净数据的假设而设计的
1.2 Label Noise Learning
在集中式的机器学习中,已经提出了很多方法来处理标签含噪声的问题,大致可以分为以下四类:
- 标签转换矩阵(Label transition matrix):估计每个标签类翻转到另一个类的概率
- 鲁棒正则化(Robust regularization)
- 鲁棒损失函数(Robust loss function)
- 筛选干净样本(Selecting possibly clean samples):在每次迭代中减少对噪声标记样本的关注,从而提高对干净样本的拟合效果
上述解决标签噪声的方法主要是在集中式训练的情况下。在联邦学习场景,Server无法直接访问Client的私有数据集,同时模型异构的场景下,不同的模型架构会导致决策边界不一致和噪声模式不同的问题
1.3 Motivation
作者认为,噪声标签在联邦学习框架下产生的新问题是:全局模型需要处理来自有噪声客户端的噪声反馈
针对模型异构问题的策略:
- 构建一个公共数据集,并将该数据集分别输入到不同客户端的异构模型中,得到不同分布的输出,再将这些分布对齐以学习全局信息
针对噪声标签问题的策略:
- 在客户端训练阶段,对称地使用交叉熵损失和反向交叉熵损失,以避免在学习所有类时过拟合噪声样本
- 为降低含噪客户端对其他客户端的影响,提出了一种新的加权方法,即Client Confidence Re-weighting (CCR),以减少含噪客户端对全局信息的贡献。CCR的基本思想是通过loss值和loss的递减速度量化Client上数据集的标签质量,然后自适应地分配各Client的权重

2 Method
2.1 Problem Definition
假设有
每个客户端的数据集定义为
服务端有一份公共数据集
此外,每个客户端还有一部分带噪声的数据集
由于每个客户端模型异构,所以对于含噪标签的决策边界也不一样,因此客户端既需要考虑自己的噪声,还需要考虑其他客户端上的噪声,问题可被定义为计算一组最优模型参数,可定义为如下表达式:

- 在公共数据集上对齐每个模型的知识分布
- 用SL Loss来缓解客户端对本地噪声的过拟合
- 对客户端进行自适应、个性化地加权,以降低含噪客户端的影响
2.2 Heterogeneous Federated Learning
这部分讲的是Server端的工作
在
计算出客户端
原文中这部分表述略有歧义,按照KL散度的定义式
的分布对应真实分布, 的分布对应观测到的样本分布,顺序反了,此处公式已更正
客户端
2.3 Local Noise Learning
这部分讲的是Client端的工作
为降低本地噪声的影响,本文使用了对称交叉熵学习(Symmetric Cross Entropy Learning)的方法
Ref: Symmetric cross entropy for robust learning with noisy labels
2.3 Client Confidence Re-weighting
客户端置信度重新加权,Client Confidence Re-weighting(CCR),也是Server端的工作
CCR的作用在于减少含噪客户端对干净客户端的影响,执行步骤如下:
第一步:评估标签质量
计算每个客户端的本地模型
通过SL损失的下降速度来量化学习效率。将客户端
两者相乘,客户端的置信度表示为:
在协作学习阶段,每轮开始的时候都会先按照客户端的置信度给每个客户端分配不同的权重,表示为:
加权正则化则可以使标签质量差、学习效率低的噪声客户端的知识最小化
动态加权后
2.4 Summary
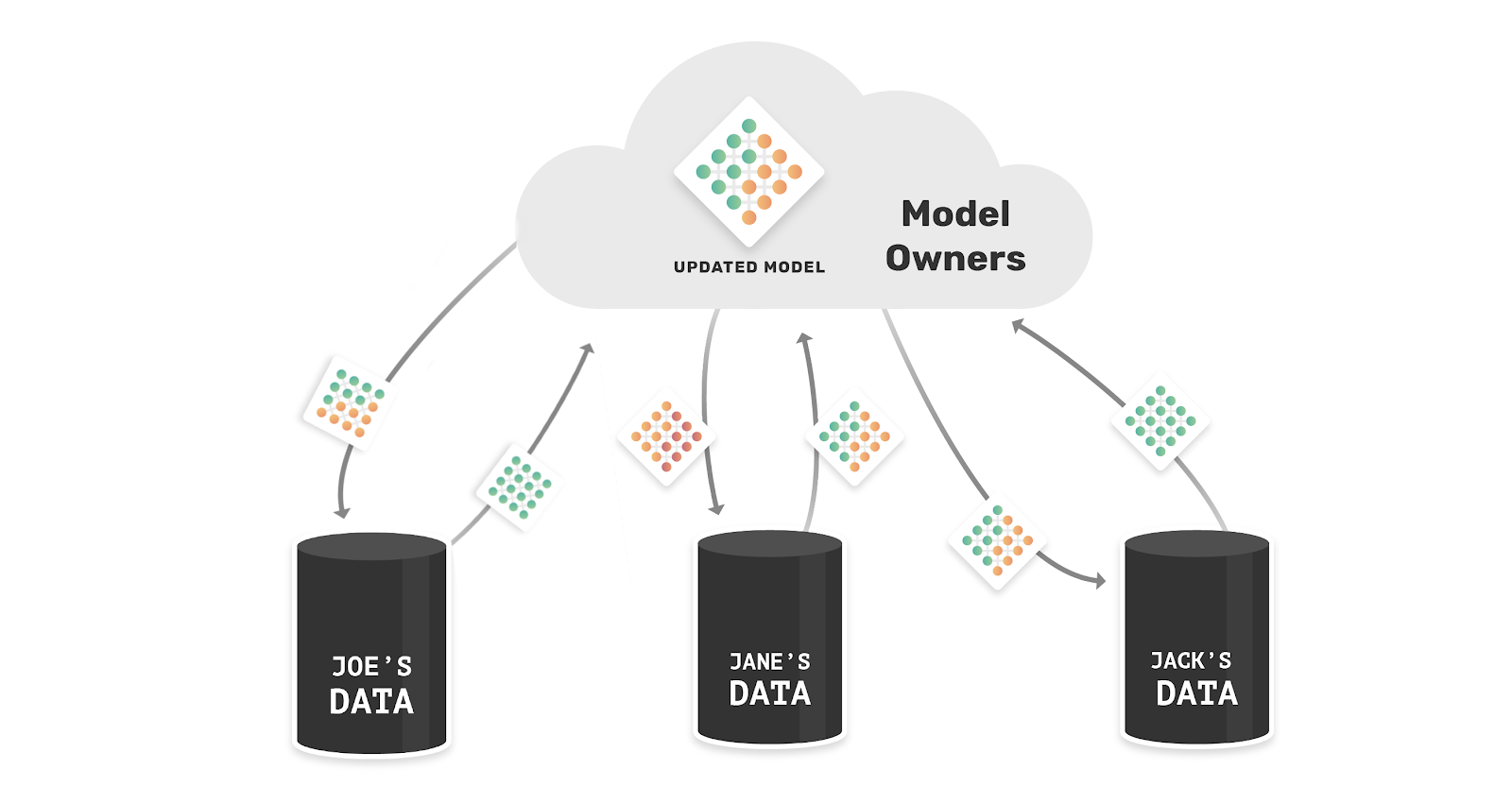
总体流程图如下

训练步骤为:
- 每个客户端
用私有的含噪数据集 训练本地模型 并得到一个预训练模型 - 在协作学习中,客户端
和其他的客户端 对齐反馈分布(即公共数据集输入模型后在logit层的输出,用KL散度量化当前客户端和其他客户端输出分布的差异)。通过这种方式可以基于和其他客户端的差异来调整当前客户端的学习方向,而不是简单地学习全局知识。对应图中Eq. 1&2 - 为减轻本地噪声的影响,用SL损失更新本地模型。对应图中Eq. 8
- 采用损失和损失下降率来衡量私有数据集的标签质量和客户端本地模型的学习效率,然后根据标签质量和模型学习效率计算客户端置信度。对应图中Eq. 9&10&11
- 当从其他客户端那里学习知识分布时,根据前一步骤计算的客户端置信度对参与者进行重新加权。对应图中Eq. 12&13
- 通过个性化加权,可以调整联邦系统中噪声客户端的参与度,避免了通信过程中噪声的影响。然后执行全局更新。对应图中Eq. 14
3 Experiments
3.1 Setting
数据集和模型
数据集:
- CIFAR10(Client)
- CIFAR100(Server)
模型:
- 模型异构场景:ResNet10、ResNet12、ShuffleNet、Mobilenetv2
- 模型同构场景:ResNet12 * 4
噪声类型
用噪声转移矩阵将噪声添加到数据集中。
- 对称翻转:原始的类标签将以相等的概率翻转到任何的错误类标签上
- 配对翻转:原始的类标签只会被翻转到一个非常相似的错误类别中
实验细节
- 数据集规模:私有数据集有
个标签,公共数据集有 个标签 - 模型异构场景下协作学习轮次
。客户端本地的epoch次数设置为 - 噪声率
, , - 在CIFAR10中,通过将20%的训练集的标签翻转来产生噪声标签,并保持测试集的标签不变来测试鲁棒性
Baseline
- 模型异构场景对比:FedMD、FedDF
- 模型同构场景对比:FedMD、FedDF、FedAvg
3.2 Ablation Study
在不同的噪声率下对3个模块进行消融:HFL、SL、CCR

3.3 Comparison with SOTA Methods
Baseline指的是不使用FL,客户端仅在私有数据集上训练本地模型的方法。
模型异构场景(

模型同构场景

4 Conclusion
4.1 Contribution
整体行文逻辑缜密,阅读观感较好,思路也挺好理解
说回内容,提出的方法充分考虑了个性化联邦场景下客户端含噪声标签的情况,然后提出的3个模块方法能够较好地协作发挥作用
4.2 Discussion
在客户端用CIFAR10作为私有数据集的情况下,服务端用CIFAR100的子集作为公共数据集是否会存在两边数据集有部分重合或很相似的问题,假设公共数据集和私有数据集的构造类别/方式差异很大,那么这种方法还能有效吗
相较于其他框架,RHFL的服务端显然凭借公共数据集拿到了更多信息,这样比较是否公平呢
在模型异构场景,目前只用了4个客户端,如果客户端数量进一步扩充,是否仍能够保持鲁棒性