【论文笔记】FedAvg
0 Paper Info
原文地址:Communication-Efficient Learning of Deep Networks from Decentralized Data
录用期刊:Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR
录用年份:2017
1 Introduction
现代移动设备可以产生大量用于训练模型的数据,而训练好的模型又可以极大地改善设备上的用户体验。例如,语言模型可以提高语音识别和文本输入,图像模型可以自动选择好的照片。然而,这些丰富的数据往往对隐私敏感或者数量庞大,亦或两者兼而有之,在这种情况下使用传统的、将所有数据集中在同一个地方进行模型训练的方法会受到诸多限制。本文提出了一种替代方案,即将训练数据分散在移动设备上,并通过聚合本地计算的更新来学习共享模型。这种去中心化的方法被称为联邦学习(Federated Learning)
1.1 Federated Learning
联邦学习的理想问题具有以下特性:
- 对来自移动设备的真实世界数据的训练比对数据中心中通常可用的代理数据(即通过某种方式加密或混淆的数据,亦或是匿名数据)的训练具有明显的优势
- 这些数据对隐私敏感的程度较大(与模型的大小相比,这也是联邦学习区别于一般的分布式机器学习的特点之一)
- 对于受监督的任务,数据上的标签可以从用户交互中自然推断出来(即可较容易地获得标定数据)。
1.2 Privacy
本文认为相较于集中式的模型训练方法,联邦学习具有天然的隐私保护优势:
在集中式的模型训练中,即使发送的是匿名数据,与其他数据的连接也可能将用户的隐私置于风险之中(而联邦学习通过发送梯度则可以有效地降低这种风险)
1.3 Federated Optimization
联邦学习本质上是一种带有隐私保护机制的分布式机器学习策略,所以会具有一些与经典分布式优化问题相不同的关键特性:
- Non-IID:非独立同分布数据。不同设备上采集的数据会基于使用人的习惯而产生明显的个性化偏差,且同一使用人在不同应用和场景下产生的数据可能会有前后关联性,所以这种数据是非独立同分布的(注意:非独立同分布包含了非独立同分布、独立非同分布、非独立非同分布的情况)
- Unbalanced:一些用户会比其他用户更频繁地使用该服务或应用程序,从而导致不同数量的本地训练数据
- Massively distributed:参与整个优化过程的用户数 > 每个用户持有的平均数据量
- Limited communication:移动设备通常会不在线,或是有着较高的通信代价
2 Method
2.1 FedSGD
本文自己提出的baseline,思想来源于SGD(随机梯度下降)
具体执行过程为:
- Server初始化模型参数
- Server同步模型参数
置每个Client - 每个Client用自己的数据
执行epoch为1的训练和参数更新(即使用所有数据进行单次训练) - 每个Client将更新后的参数
发送至Server - Server基于每个客户端的数据数量加权聚合模型参数,得到新参数
- 返回至第2步开始循环
FedSGD可视为FedAvg中Client epoch=1的特殊情况
2.2 FedAvg

区别于FedSGD,FedAvg在Client端的epoch可以有多次
3 Experiments
3.1 Setting
图像数据集:MINIST、CIFAR10
语言数据集:莎士比亚全集(The Complete Works of William Shakespeare)
3.2 Results
预实验:
利用隐藏层数量为2的MLP和CNN在IID和Non-IID场景下对MNIST数据集进行分类,表格中的数值代表在限制时间范围内达到给定准确率所需的时间,横杠代表未在限制时间范围内达到给定准确率。
这部分实验是为了说明Non-IID会导致模型性能的下降,但同时可以看到,
PS:这篇文章中Non-IID的划分方法为:按照label对数据集进行排序,然后均分为200份(一份有300张图片),然后每个Client分发两份。现阶段可用Dirchlet Distribution进行更合理的划分
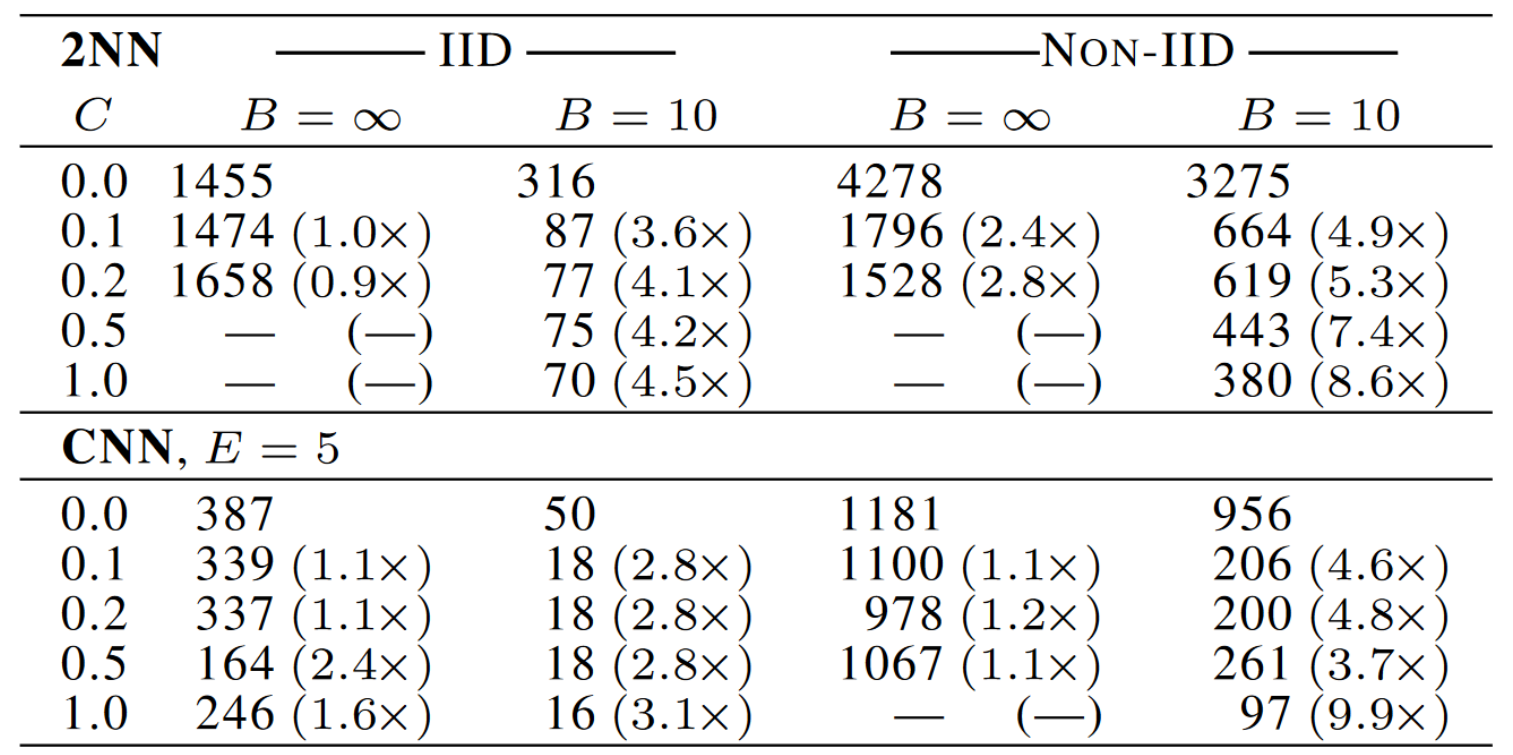
C:单个round中参与更新的Client的百分比(0代表只有一个Client参与);E:Client在单次round中本地更新的epoch数量;B:Client的batch size
FedSGD和FedAvg在MNIST-CNN和SHAKESPEARE-LSTM上的对比实验
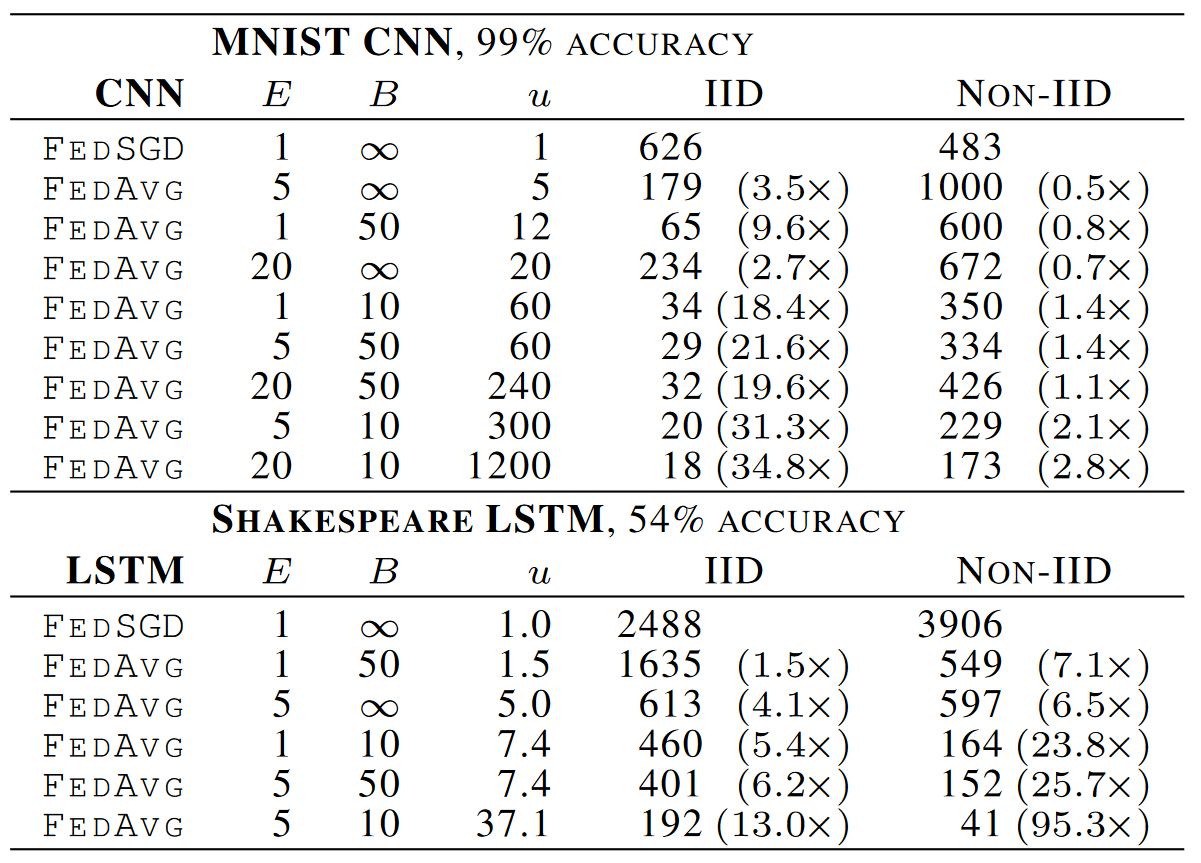
u: 单个round中各个client epoch的和
并行性实验
这部分主要讲参数C的选取,由于在大部分情况下增加单个round的client数量对提高收敛速度并没有很大的帮助,所以找了个效率和准确率的平衡点,取C=0.1
提高client的计算量
固定learning rate,减小client的batch size或者增加epoch,观察对收敛效果的影响
上侧图是MNIST-CNN,下侧图是SHAKESPEARE-LSTM,灰线是target accuracy
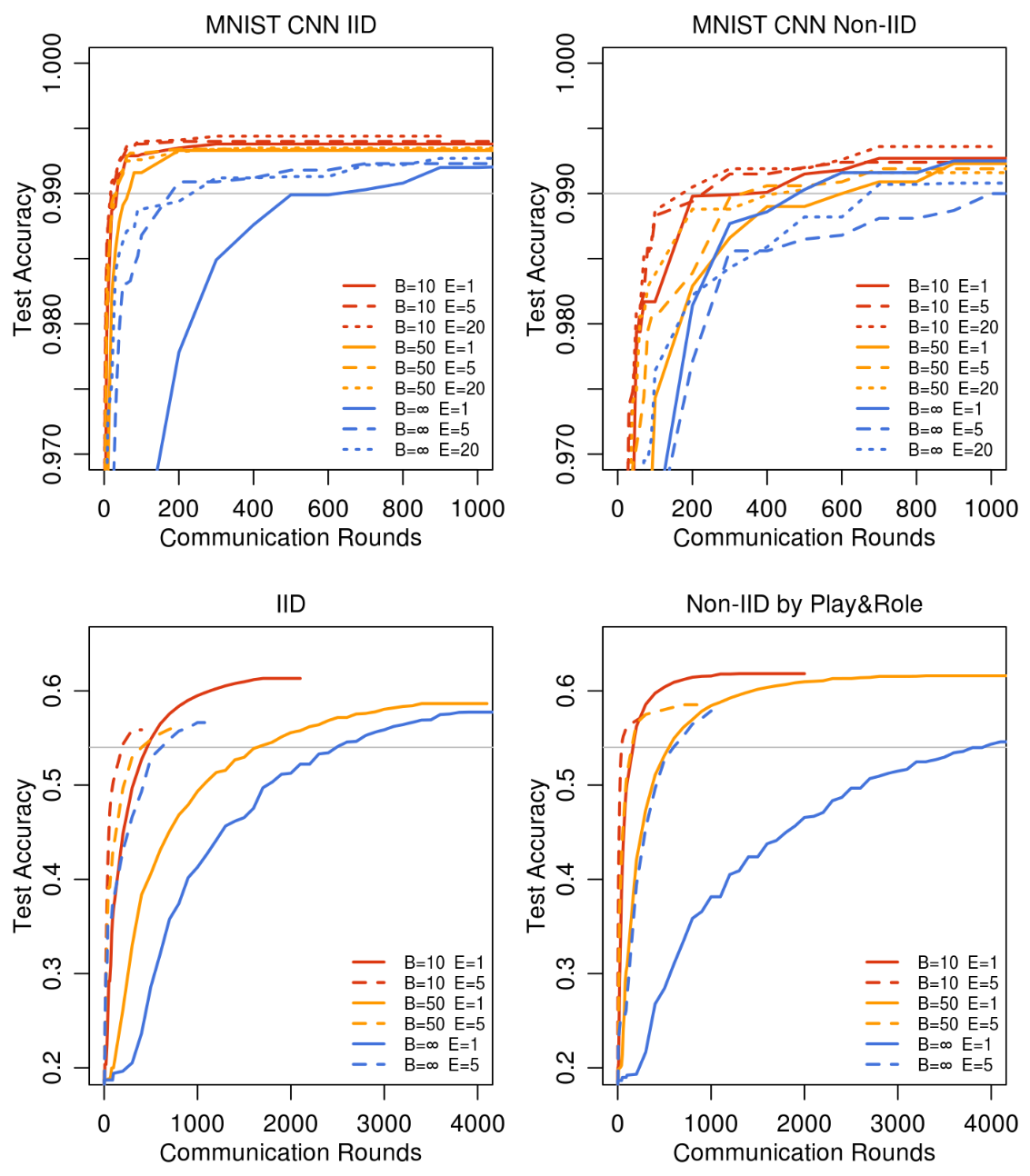
Client Epoch
固定learning rate=1.47,C=0.1,B=10(小批量确保收敛),调整E,还是基于上述两种场景实验
可以看到E=5时效果最好,并不是越大或者越小越好

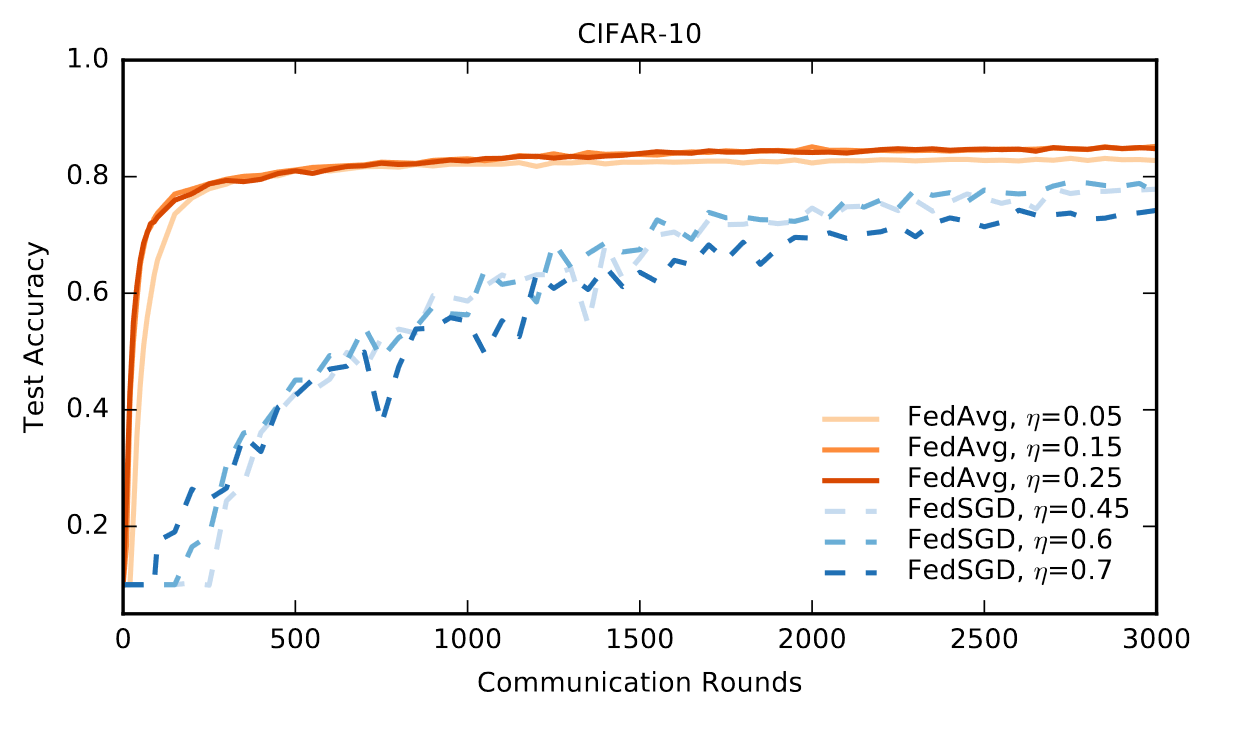
CIFAR 10 Experiment
在不同学习率的情况下FedAvg相较于FedSGD都有更快的收敛速度
更大的语言测试数据
从社交网络采集的大小为1000万的训练集,进行Next Word Prediction,FedAvg的收敛速度和最终准确率也均高于FedSGD,且方差更小
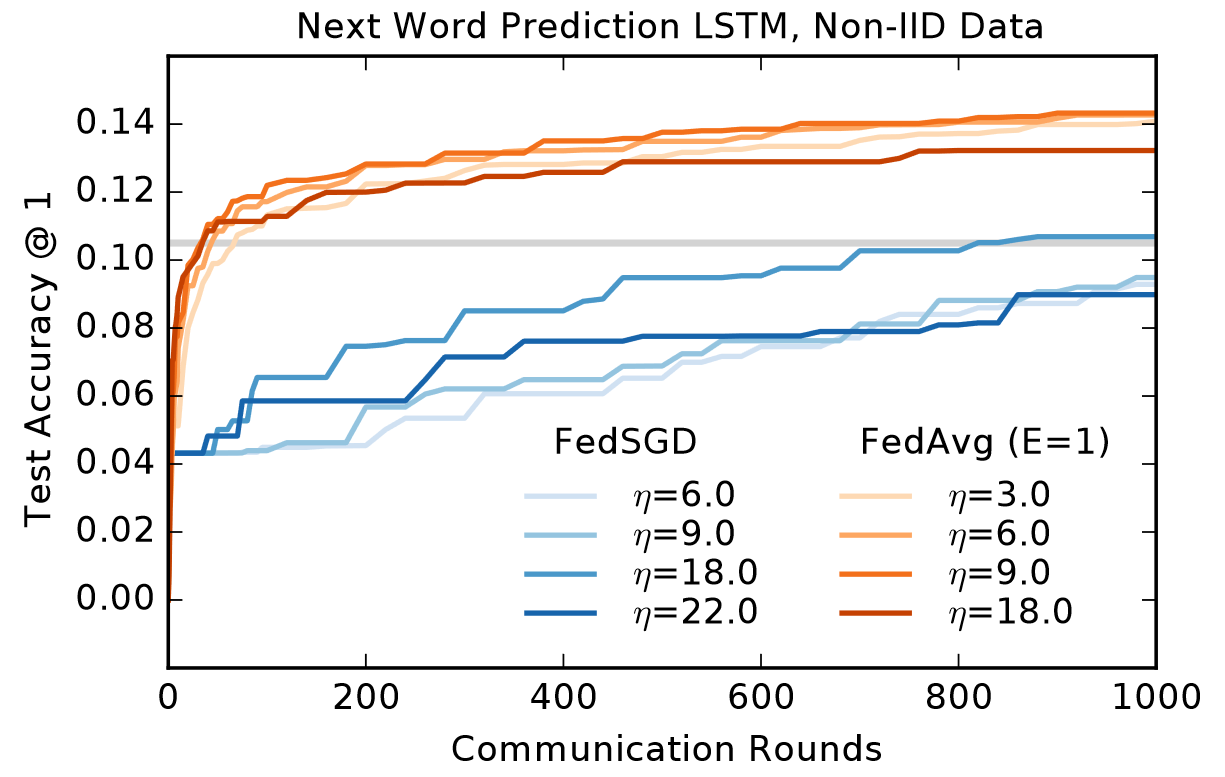
在这种场景下,FedAvg上E=1的效果略优于E=5
4 Conclusion
4.1 Contribution
联邦学习的开山之作,证明带隐私保护机制的分布式训练(利用梯度代替数据进行去中心化学习)在IID和Non-IID场景下是可行的(即模型可以优化至收敛且精度损失在可接受范围内,同时对不同架构的模型有良好的兼容性)
4.2 Discussion
以今天的视角来看,存在聚合函数仍有改进空间(仅根据数据量来衡量client的权重有很大的局限性)、梯度可以被逆向所以并不能完全保护隐私(目前常用的方案有差分隐私、同态加密等)等问题